
MedGemma: Google’s Open Medical AI Model
Harnessing Multimodal and Text-Only Models for Accessible, High-Performance Clinical Insights

Google DeepMind recently unveiled MedGemma at Google I/O 2025, marking a major milestone in open-source medical AI. Announced in May 2025, MedGemma builds on the Gemma 3 architecture and it’s a successor to Gemma 2 which is designed to understand and analyze both medical images and text at scale. This model promises to accelerate research, diagnostics, and clinical decision support worldwide.
Gemma 3 introduced lightweight, high-performance multimodal capabilities optimized for edge deployment, improving on Gemma 2’s larger, less efficient footprint. MedGemma inherits these optimizations and specializes them for healthcare, joining other domain‑specific variants like SignGemma (for sign language) in Google’s open-weights ecosystem.
Model Variants
MedGemma comes in two flavors, each instruction‑tuned for ease of use:
MedGemma 4B (Multimodal)
Parameters: 4 bn
Capabilities: Processes images and text in a unified pipeline
Vision Encoder: SigLIP, pre-trained on de-identified chest X‑rays, dermatology, ophthalmology, and pathology images
Link: developers.google.com
MedGemma 27B (Text-Only)
Parameters: 27 bn
Capabilities: Deep clinical-text comprehension and reasoning
Both variants are available in pre-trained (pt) and instruction‑tuned (it) forms via Hugging Face and Google Cloud Model Garden
The MedGemma 4B model actually “looks” at pictures and reads text. Its vision part (called SigLIP) learned from lots of different medical image collections such as chest X‑rays (from the MIMIC‑CXR database), radiology questions and answers (VQA‑RAD), cancer pathology slides (CAMELYON), and various tumor scans (TCGA). At the same time, its language part practiced on a wide range of real-world medical documents, such as radiologist reports and doctors’ clinical notes.
By contrast, the larger MedGemma 27B model focuses only on text. It was first trained on huge libraries of medical writing including textbooks, research papers, case reports and then given special clinical “instructions,” so it knows how to answer questions like a seasoned healthcare professional.
Running MedGemma in Colab
You can try this interactively go to this GitHub link and click on run in a Colab notebook. Make sure you have account on huggingface and generated a read only access token.
Instead of walking through each cell line by line, here’s a simplified summary of what the notebook covers and summarized by Gemini:
This notebook serves as a quick start guide for utilizing MedGemma, a set of Gemma 3 models specifically trained for medical applications. It demonstrates how to perform inference with these models from Hugging Face for both image-text and text-only tasks.Here's a breakdown of what's happening in the notebook and the corresponding outputs:Setup and Authentication: The initial cells handle the necessary setup. This includes setting up the environment, authenticating with Hugging Face using a stored token (which was successful based on the execution), and installing the required Python libraries (also completed successfully as shown in the pip install output).Model Loading and Configuration: The notebook then proceeds to set the model variant (MedGemma 4B in this case) and configure the model loading with quantization to optimize memory usage.Image-Text Inference: This section demonstrates how to use the model with both the Hugging Face pipeline API and direct model interaction for image-based tasks. An example using a chest X-ray is provided. The code successfully loaded the model and processed the image. The output from both the pipeline and direct methods was a detailed description of the X-ray, concluding that it appeared normal.Text-Only Inference: This section focuses on text-based tasks. An example is given for differentiating between bacterial and viral pneumonia. Similar to the image-text section, inference is performed using both the pipeline API and direct model interaction. The code successfully loaded the model and processed the text prompt. The outputs from both methods provided comprehensive explanations of the differences between the two types of pneumonia, covering symptoms, onset, and treatment.In essence, the notebook walks through the process of getting started with MedGemma on Hugging Face, showing how to load the model and perform inference on both image and text data, with successful execution and relevant outputs for the provided examples.Here’s the output generated when a chest X-ray image was provided as input and the model was asked to describe its findings.
{kind=link}
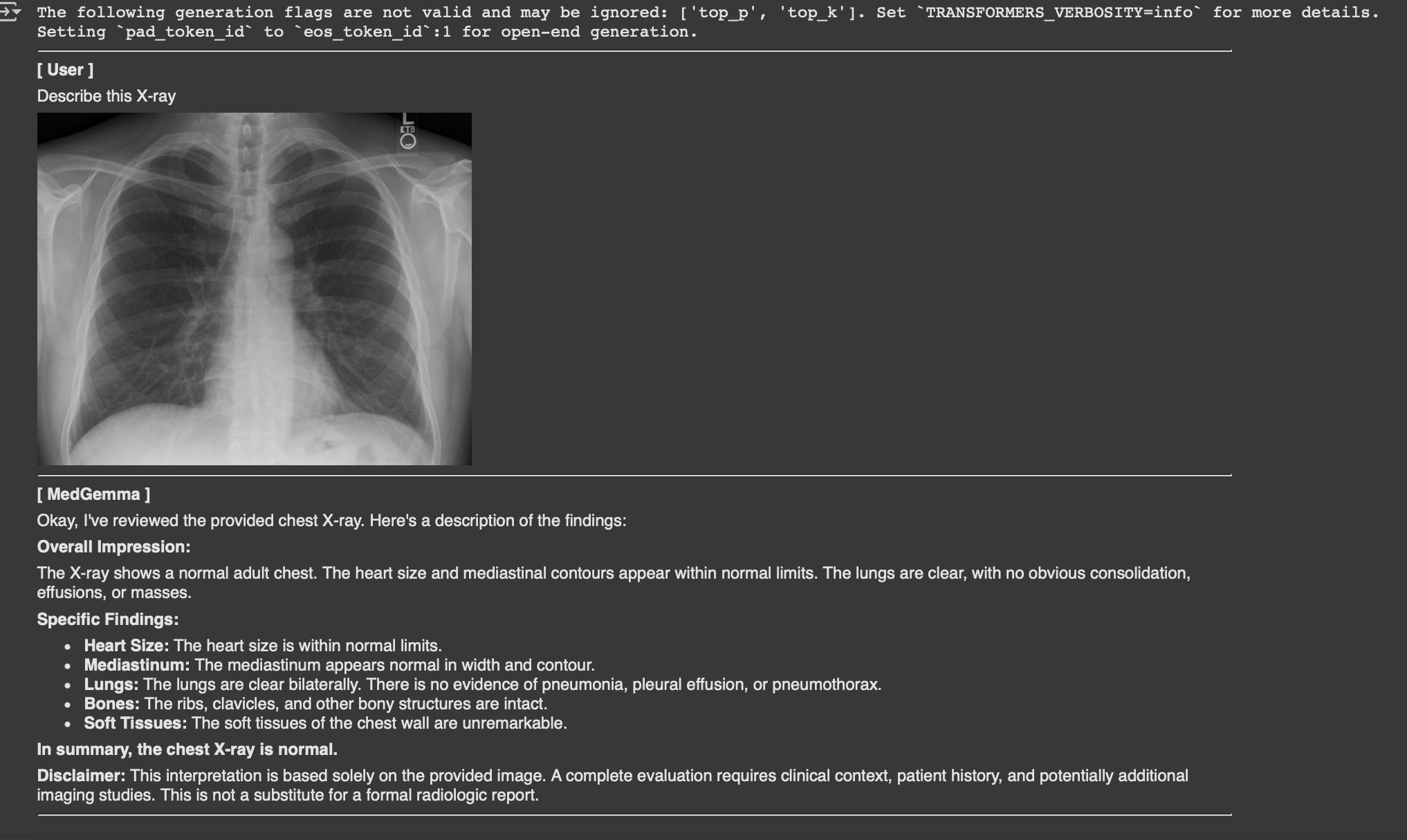
Following the image-to-text example, this section demonstrates how to use MedGemma 27B for a text-only task.
The code sets up a clinical questions “How do you differentiate bacterial from viral pneumonia?” and defines the model’s role as a helpful medical assistant. Depending on the model variant, it also include a silent reasoning instruction and adjust the response length. The input is structured as a system prompt and a user query, then passed to the model for generating a detailed medical explanation.
Here is the output:

I went ahead and checked (tricked) if the model could provide treatment options along with the specific drug molecules used and it delivered impressively detailed results. Here is the output:
This kind of output reinforces how transformative open-source medical AI can be.
As these models continue to evolve, they have the potential to become powerful assistants for clinicians, trusted learning companions for medical students, and a reliable first point of reference in regions with limited access to healthcare.
But healthcare is a deeply sensitive and high-stakes field where accuracy, context, and accountability matter immensely.
Responsible use, thorough validation, and expert oversight aren't just best practices are essential safeguards.
After all, patients used to Google their symptoms earlier, now they’ll just ask AI.