
How AI Is Learning to Diagnose Like Doctors
Inside Microsoft’s groundbreaking study that makes AI reason like a real physician, not just memorize medical exams

Microsoft researchers introduced Sequential Diagnosis with Language Models, turning 304 clinical cases into a step-by-step benchmark called SD‑Bench. It mirrors how doctors think starting with a short case summary, then ordering tests and asking questions. To guide this process, they created MAI Diagnostic Orchestrator (MAI‑DxO), which helps the AI make smart, cost-effective decisions. A separate set of 56 newer cases helped confirm the results.
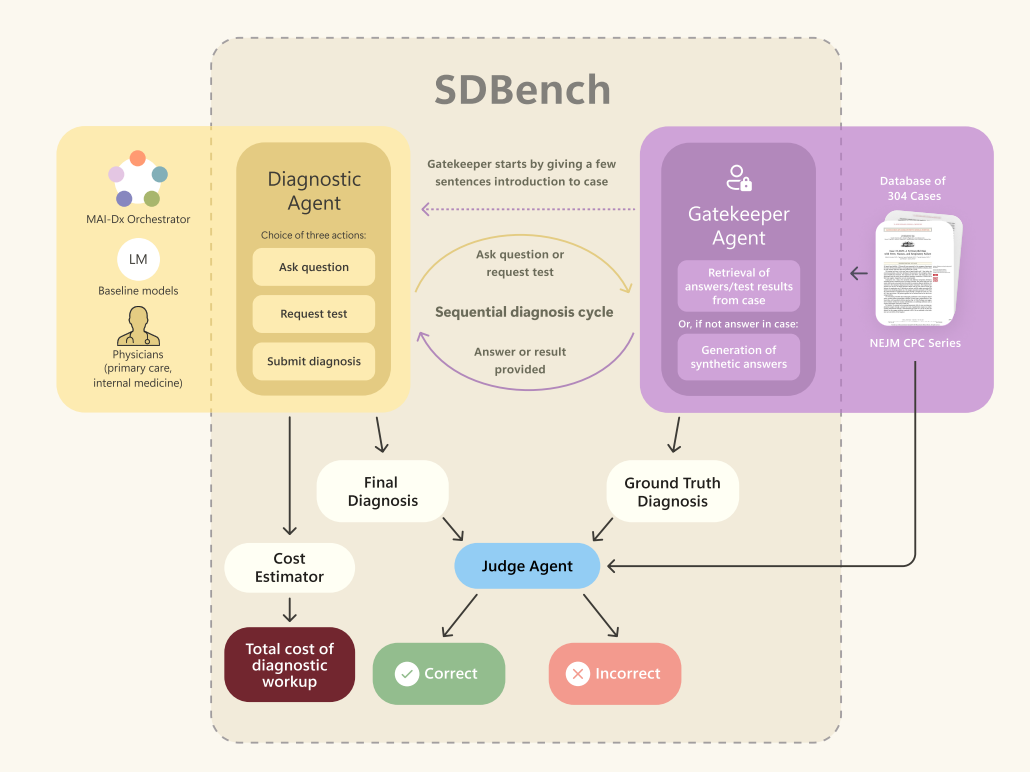
Image credits: Microsoft AI (https://arxiv.org/pdf/2506.22405 )
Why Real Diagnosis Needs a Conversation
Most medical AI models today are tested like students taking a multiple-choice exam. Feed them a full case and ask them to guess the diagnosis. But real-world diagnosis doesn’t work that way. Doctors rarely get everything at once. They start with a short summary-maybe just “abdominal pain” or “shortness of breath” and then ask questions, run tests, follow clues, and gradually narrow things down.
This is where Zero-shot / one-shot AI falls short. It doesn’t simulate the doctor’s journey. It skips the reasoning. That’s why the researchers behind SD‑Bench and MAI‑DxO designed a different approach. Instead of giving the AI all the data at once, they made it work for it-one question or one test at a time, just like a physician would. For example, in a case involving a patient with joint pain and fatigue, the model had to ask for specific lab results and imaging before reaching a diagnosis of lupus-something it could never have guessed from the opening summary alone.
This back-and-forth makes the AI not just smarter, but safer. It’s not just memorizing-it’s thinking. And that’s what makes it exciting.
Meet SD‑Bench & MAI‑DxO
Researchers created Sequential Diagnosis Benchmark (SD‑Bench) by converting 304 complex cases from the NEJM into interactive challenges. In each case:
An AI or doctor reads a short summary.
They ask for more details or choose a test.
A “gatekeeper” reveals new findings only when prompted.
They repeat steps 2–3 until they decide on the diagnosis.
Alongside SD‑Bench, they built MAI Diagnostic Orchestrator (MAI‑DxO), a virtual panel that guides the AI through this process. It proposes likely diagnoses, picks high‑value, low‑cost tests, and even audits its own reasoning before concluding.
How the AI Actually Thinks

Beyond the technical setup, the real innovation lies in how MAI‑DxO guides the AI to act more like a thoughtful physician. It doesn’t let the model just blurt out a diagnosis. Instead, it nudges it to ask better questions, consider test costs, and pause to reflect. For example, instead of defaulting to an MRI or CT scan, the AI is encouraged to weigh whether a simple blood test could narrow down the possibilities.
This disciplined reasoning is not just more cost-effective, it also mimics how experienced clinicians work under real-world constraints. And crucially, it lets the model correct itself. Before locking in a final answer, the AI is asked: does your diagnosis explain all the findings? That final self-check step boosts safety which is a big deal in high-stakes situations like diagnosing sepsis or ruling out stroke.
Key Results

The study compared six families of AI models-OpenAI’s o3, Gemini, Claude, Grok, DeepSeek, and Llama-both on their own and under MAI‑DxO control. They also had 21 practicing doctors in the US and UK work the same cases without colleagues or textbooks.
Standalone LLMs averaged around 20 % accuracy.
Generalist physicians reached about 20 % accuracy.
MAI‑DxO with OpenAI o3 hit 80 % accuracy in standard mode and 85.5 % in high‑accuracy mode.
Cost reduction was 20 % lower than doctors and 70 % lower than off‑the‑shelf o3.
Why It Matters
This work shows that AI can do more than pass medical exams, it can think aloud, reason step by step, and question itself. That’s a big shift.
For patients, this could mean faster and safer diagnoses. In one case, the AI spotted liver issues early using just routine lab work skipping unnecessary scans.
Of course, we’ll need to see how it performs in different clinics and with more routine cases.
Will it be as clear and reliable in real-world settings?
That’s something we’ll likely find out soon.
To move from lab to clinic, this approach needs real-world trials and peer review. Future work should include everyday cases, collaborative workflows (reflecting how doctors really work), and tests in diverse healthcare settings to confirm both accuracy and cost savings across populations.
Try It Yourself: Sample Prompts
Attempting the prompts on GROK 3

Follow up on differential diagnosis

Follow up on CBC test

Follow up confirmation on ANA test

Follow up confirmation on anti-dsDNA and anti-Smith antibodies test

Final self-audit check

The model now has all the clues but remember, even a great answer here doesn’t replace real medical expertise. Use this as a learning tool, not a diagnosis.